Voynich Manuscript is a Medieval codex hand-written in an unknown writing system. For over one century since the document was rediscovered, it has attracted numerous historians, linguists and computer scientists over the world to interpret. However, nobody has deciphered this codex till now. By virtue of the power of deep learning, natural language processing (NLP) has been shooting through the roof in the past decade. Therefore, employing NLP approaches to analyse the Voynich Manuscript is a promising direction. Even though NLP have not completely unravelled the riddle, such methods have made significant progress on understanding Voynich text. Hopefully, this project can make contributions to the Voynich research as well.
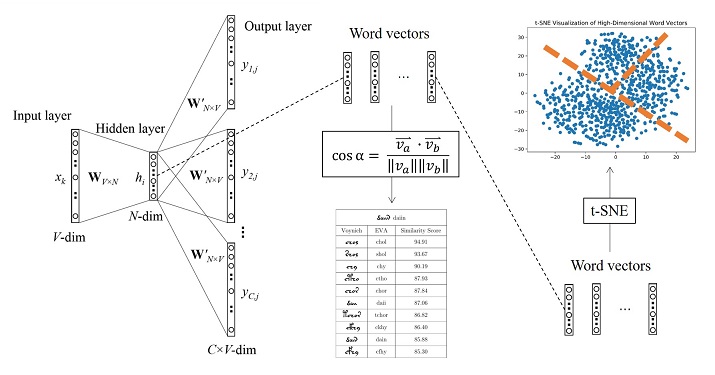
There are two contributions of this project. For one thing, this project employs word2vec to build a Voynichese word embedding space, aiming to determine the level of similarity among any pair of word by evaluating the angle between their vectors. Generally, the vector cross angle between a pair of synonyms is usually very close, which is helpful for researchers to judge synonyms according to this angle. The second goal is to augment the text dataset since the original one is too scarce for researchers to conduct deep learning and computational linguistic analysis. This achievement is meaningful for those computer scientists who are looking forward to explore the dataset with deep learning language models.
 Download the word embeddings model on python.gensim
Download the word embeddings model on python.gensim
 View/
Download the augmented Voynich text set
View/
Download the augmented Voynich text set